潮人地東莞seo博客小編下面跟大家分享關于seo優化博客:百度Spider抓取系統的基本框架介紹等問題,希望seo專員在做seo優化的過程中有所幫助,內容僅供參考。
今天潮人地東莞seo博客為朋友們介紹一下百度Spider抓取系統的基本框架,這篇博文也是小編轉載自百度站長學院內第一篇官方發布的內容。內容正文部分如下:
互聯網信息爆發式增長,如何有效的獲取并利用這些信息是搜索引擎工作中的首要環節。數據抓取系統作為整個搜索系統中的上游,主要負責互聯網信息的搜集、保存、更新環節,它像蜘蛛一樣在網絡間爬來爬去,因此通常會被叫做“spider”。例上海seo技術外包如我們常用的幾家通用搜索引擎蜘蛛被稱為:Baiduspdier、Googlebot、Sogou Web Spider等。
seo博客相關推薦閱讀:seo推廣技巧之:日常seo優化技術操作的主要內容是怎樣
Spider抓取系統是搜索引擎數據來源的重要保證,如果把web理解為一個有向圖,那么spider的工作過程可以認為是對這個有向圖的遍歷。從一些重要的種子 URL開始,通過頁面上新華區seo技術培訓的超鏈接關系,不斷的發現新URL并抓取,盡最大可能抓取到更多的有價值網頁。對武漢seo技術哪個最好于類似百度這樣的大型spider系統,因為每時 每刻都存在網頁被修改、刪除或出現新的超鏈接的可能,因此,還要對spider過去抓取過的頁面保持更新,維護一個URL庫和頁面庫。
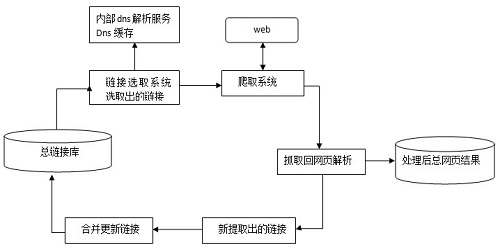
下圖為spider抓取系統的基本框架圖,其中包括鏈接存儲系統、鏈接選取系統、dns解析服務系統、抓取調度系統、網頁分析系統、鏈接提取系統、鏈接分析系統、網頁存儲系統。Baiduspider即是通過這種系統的通力合作完成對互聯網頁面的抓取工作。
以上是潮人地東莞seo博客跟大家分享關于seo優化博客:百度Spider抓取系統的基本框架介紹等問題,希望能對大家有所幫助,若有不足之處,請諒解,我們大家可以一起討論關于網站seo優化排名的技巧,一起學習,以上內容僅供參考。

















